
What is POLARDB, Architecture and Benefits
ApsaraDB for POLARDB is a next-generation relational database service developed by Alibaba Cloud.

ApsaraDB for POLARDB is a next-generation relational database service developed by Alibaba Cloud. It is compatible with MySQL, PostgreSQL, and Oracle databases. With superior performance in storage and computing, ApsaraDB for POLARDB can meet the diverse requirements of enterprises.
An ApsaraDB for POLARDB cluster has a maximum storage space of 100 TB and can be configured with a maximum of 16 nodes.
ApsaraDB for POLARDB uses a storage and computing-separated architecture, in which all compute nodes share one copy of data. It can achieve vertical scaling within minutes and crash recovery within seconds. It ensures global data consistency, and offers free services for data backup and disaster recovery.
ApsaraDB for POLARDB integrates the benefits of commercial databases and open source cloud databases. Commercial databases are stable, reliable, high-performance, and scalable while open source databases are easy to use and self-iterative. For example, the time a POLARDB for MySQL database takes to return results for a query reduces by five times than that a MySQL database takes. However, the cost of a POLARDB for MySQL database is only 10% that of a MySQL database.
Cluster architecture with separate storage and computing: ApsaraDB for POLARDB adopts a cluster architecture. Each cluster contains one read/write node (primary node) and multiple read-only nodes. All nodes share the data in a Polar store by using a distributed Polar file system.
Read/write splitting: POLARDB for MySQL uses a built-in proxy to handle external requests. When apps use a cluster address, the proxy handles all requests sent from the apps before forwarding the requests to nodes. You can use the proxy for authentication and protection and use it to achieve automatic read/write splitting.
The proxy can parse SQL statements, send write requests (such as transactions, UPDATE, INSERT, DELETE, and DDL operations) to the primary node, and distribute read requests (such as SELECT operations) to multiple read-only nodes. With the proxy, apps can access POLARDB for MySQL as easily as they access a single-node MySQL database. The proxy only supports POLARDB for MySQL. We are working on support for POLARDB for PostgreSQL and POLARDB compatible with Oracle.
Terms
Familiarize yourself with the following terms to gain a better understanding of ApsaraDB for POLARDB. This helps you to find optimal purchase strategies and use the ApsaraDB for POLARDB service based on your needs.
- Cluster: ApsaraDB for POLARDB adopts a cluster architecture. Each cluster contains one primary node and multiple read-only nodes.
- Region: specifies the region in which a data center resides. You can achieve optimal read/write performance if ApsaraDB for POLARDB clusters and ECS instances are located in the same region.
- Zone: A zone is a distinct location that operates on independent power grids and networks within a region. All zones in a region provide the same services.
- Specification: specifies the resources configured for each node, such as 2 CPU cores and 4 GB.
Benefits
ApsaraDB for POLARDB is compatible with MySQL, PostgreSQL, and Oracle databases. ApsaraDB for POLARDB has the following benefits:
- Large storage spaceA maximum storage space of 100 TB for an ApsaraDB for POLARDB cluster overcomes the limit of a single host and alleviates the need to purchase multiple instances for database sharding. ApsaraDB for POLARDB simplifies application development and reduces O&M workloads.
- Cost-effectivenessWhen you add a read-only node in an ApsaraDB for POLARDB cluster, you only need to pay for computing resources because of storage and computing separation. In contrast, traditional databases charge you for both computing and storage resources.
- Elastic scaling within minutesYou can quickly scale up an ApsaraDB for POLARDB cluster because of storage and computing separation as well as shared storage.
- Read consistencyThe cluster address uses log sequence numbers (LSNs) to ensure global consistency in reading data and to avoid inconsistency caused by synchronization latency between the primary node and read-only nodes.
- Millisecond-level latency in physical replicationApsaraDB for POLARDB uses redo log-based physical replication from the primary node to read-only nodes instead of binlog-based logical replication to improve the efficiency and stability. No latency is incurred for databases even if you perform DDL operations for a large table, such as adding indexes or fields.
- Unlocked backupYou can back up a database with a size of 2 TB within 60 seconds by using snapshots. Backup can be performed at any time on a day without any impacts on apps. During the backup process, the database will not be locked.
Use ApsaraDB for POLARDB
You can use the following methods to manage ApsaraDB for POLARDB clusters, for example, to create clusters, databases, and accounts:
- Console: provides a visualized and easy-to-use Web interface.
- CLI: All operations available in the console can be performed by using the command-line interface (CLI).
- SDK: All operations available in the console can be performed by using the SDK.
- API: All operations available in the console can be performed by using API operations.
After creating an ApsaraDB for POLARDB cluster, you can connect to the cluster by using the following methods:
- DMS: You can connect to an ApsaraDB for POLARDB cluster by using Data Management (DMS) and develop databases on the Web interface.
- Client: You can connect to an ApsaraDB for POLARDB cluster by using a database client, such as MySQL-Front and pgAdmin.
Architecture
The architecture of the cloud-native POLARDB is shown in the following figure.
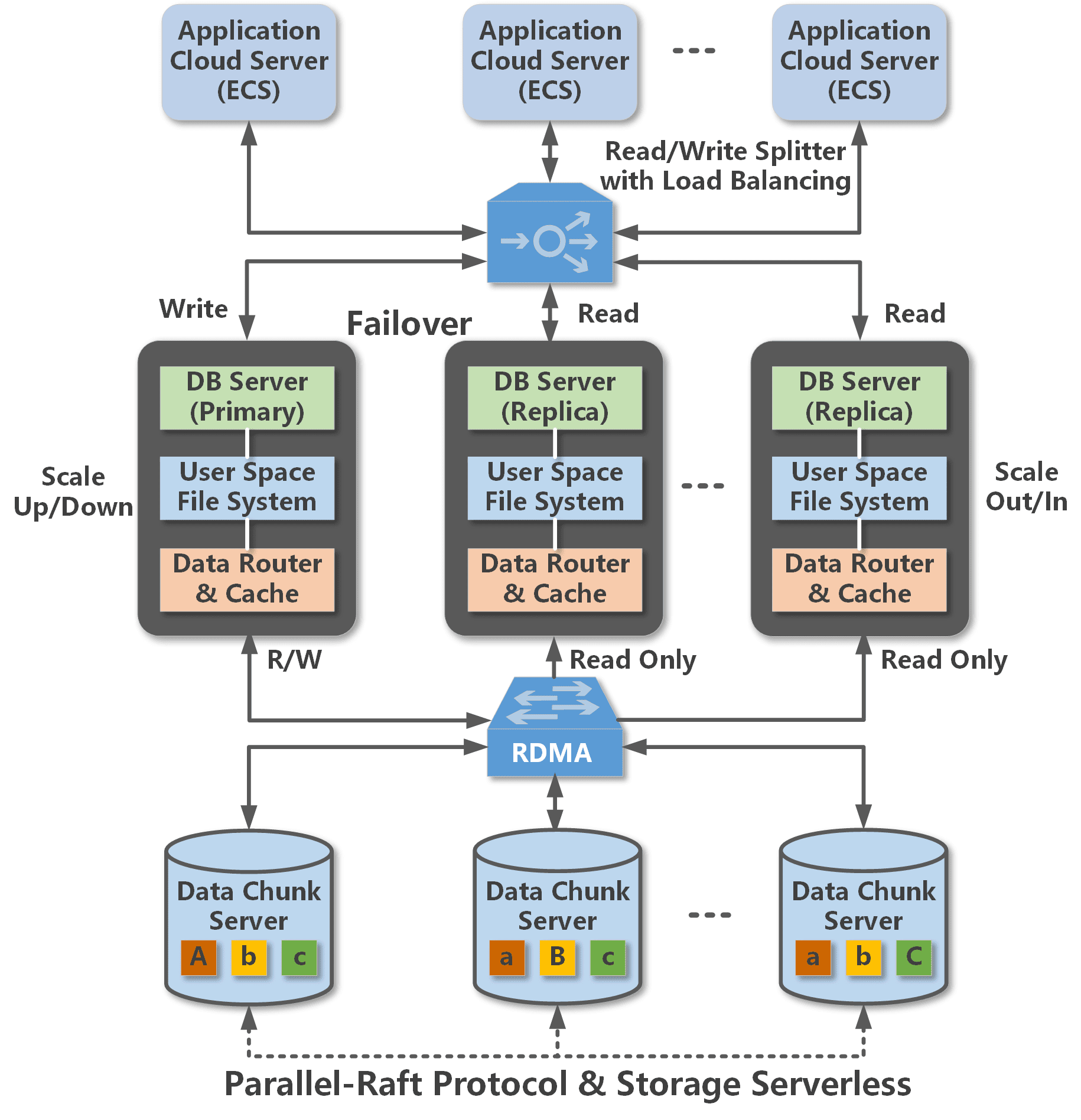
One primary instance, multiple read-only instances
A POLARDB cluster contains one primary instance and up to 15 read-only instances (with at least one read-only instance to provide active-active high availability support). The primary instance processes read and write requests, while read-only instances process read requests only. POLARDB provides highly available services by performing active-active failover targeted at the primary instance or a read-only instance.
Compute and storage separation
POLARDB separates compute processes from storage processes, allowing the database capacity to scale up and down to meet your application needs in Alibaba Cloud. DB servers are used only to store metadata, while data files and redo logs are stored in remote chunk servers. DB Servers only need to synchronize redo log metadata between each other, which significantly lowers the data latency between the primary instance and read-only instances. If the primary instance fails, a read-only instance can be rapidly promoted to be primary.
Read/write splitting
Read/write splitting is enabled for POLARDB clusters by default, providing transparent, highly available, and self-adaptive load balancing for your database. The read/write splitting feature automatically routes requests directed at the read/write splitting connection string. It passes write requests to the primary instance and passes read requests to either the primary instance or a read-only instance based on the load of each instance. This allows the database to handle large numbers of concurrent requests.
High speed network connection
To ensure strong I/O performance, high speed network connection is enabled between the DB server and the chunk server, and data are transferred using the Remote Direct Memory Access (RDMA) protocol.
Shared distributed storage
Sharing the same group of data copies among multiple DB servers, rather than storing a separate copy of data for each DB server, significantly reduces your storage cost. The distributed storage and file system allows automatically scaling up database storage capacity, regardless of the storage capacity of each single database server. This enables your database to handle up to 100 TB of data.
Multiple data replicas, Parallel-Raft protocol
Chunk servers maintain multiple data replicas to ensure reliability, and comply with the Parallel-Raft protocol to guarantee consistency among these replicas.