
An Introduction to Alibaba Cloud DataWorks
DataWorks is a product launched by Alibaba Cloud that is specifically designed with big data in mind.
DataWorks is an important Alibaba Cloud Platform as a service (PaaS) product. It offers fully hosted workflow services and a one-stop data development and management interface to help enterprises mine and comprehensively explore data value.
DataWorks uses MaxCompute as the core computing and storage engine to provide massive offline data processing, analysis, and mining capabilities.
Below is a basic introduction to the two products of DataWorks and MaxCompute, which interoperate with each other on Alibaba Cloud.
DataWorks
DataWorks is a product launched by Alibaba Cloud that is specifically designed with big data in mind. With DataWorks, you do not need to worry about cluster and operations. Rather, DataWorks serves as a single, unified solution for the development of data, data permission management and offline job scheduling. DataWorks also features real-time analytics, data asset management, and data quality and security management. One important thing to note is that DataWorks cannot be used alone and it uses the Alibaba Cloud MaxCompute as its core computational engine.
MaxCompute
The big data computing service (MaxCompute, formerly called ODPS) is a fast and fully hosted GB/TB/PB level data warehouse solution.
MaxCompute supports a variety of classic distributed computing models that enable you to solve massive data calculation problems while reducing business costs, and maintaining data security.
MaxCompute seamlessly integrates with DataWorks, which provides one-stop data synchronization, task development, data workflow development, data operation, and maintenance, and data management for MaxCompute.
MaxCompute is mainly used to store and compute batches of structured data. It provides a massive range of data warehouse solutions as well as big data analysis and modeling services. As data collection techniques are becoming increasingly diverse and comprehensive, industries are amassing larger and larger volumes of data. The scale of data has increased to the level of massive data (100 GB, TB, and even PB) that traditional software industry can not carry.
Given these massive data volumes, the limited processing capacity of a single server has prompted analysts to move towards distributed computing. However, distributed computing models are not easy to maintain and demand highly-qualified data analysts. When using a distributed model, data analysts not only need to understand their business needs but also must be familiar with the underlying computing model. The purpose of MaxCompute is to provide you with a convenient way of analyzing and processing mass data, and you can achieve the purpose of analyzing large data without having to care about the details of distributed computing.
Prerequisites
To complete the steps in this article, you will need the following:
- An Alibaba Cloud account
- Access Key and Role Access
- To buy and activate MaxCompute
we have already created an account and access key, so these steps are not included here. But below, we will show you how to purchase and activate MaxCompute, if you haven’t already.
DataWorks Features:
- Fully-hosted scheduling
DataWorks provides powerful scheduling capabilities. Based on Directed Acyclic Graph (DAG) relationships, the time-based or dependency-based tasks trigger configurations to perform tens of millions of tasks punctually and precisely daily. The multiple scheduling frequency configurations are supported by a minute, hourly, daily, weekly, and monthly basis.
The fully-hosted service eliminates all server resource scheduling concerns. The system isolates different tenants to guarantee tasks run independently.
- Supports various task types
DataWorks supports multiple task types, such as data synchronization, SHELL, MaxCompute SQL, and MaxCompute MR tasks. Complex data analysis processes are based on dependencies between tasks.
- Powered by MaxCompute, DataWorks provides powerful data conversion capabilities to guarantee high performance of big data analysis.
- For data synchronization, DataWorks relies on powerful data integration capabilities to support more than 20 types of data sources and provide stable and highly-efficient data transmission. For more information, see Data integration overview.
- Data visualization development
This product offers visualization code development and workflow designer pages. No additional development tools are required to drag and drop components to develop complex data analysis tasks. Development tasks can be performed from anywhere in the globe through Internet connection and web browsers.
- Monitoring and alarms
The O&M center provides visual task monitoring and management tools and displays global conditions in DAG format when tasks are running.
SMS alarms can be easily configured to notify the relevant alarm contact of task errors for immediate troubleshooting.
Constraints and limits
- DataWorks only supports Chrome 54 or later versions.
- Currently, DataWorks only supports SQL operations on Alibaba Cloud’s MaxCompute.
DataWorks Concepts:
Business flow
This topic describes DataWorks business flows, solutions, components, tasks, instances, submissions, script development, resources, functions, and output name concepts.
Advantages:
- Helps organize data codes from business perspectives supports code organization based on task types and multi-level sub-directories (Alibaba Cloud recommends no more than four levels).
- Provides work flow overview from business perspectives to facilitate optimization.
- Provides business flow dashboards for efficient development.
- Organizes release and maintenance based on business flows.
Solution
DataWorks offers customizable and integrable business flow solutions.
Advantages:
- Multiple business flows
- Reusable business flows for different solutions
- Comprehensive solutions for immersive development
Component
A component is a SQL code procedure template with multiple input and output parameters, SQL code procedures are generally handled by introducing one or more data table sources through filtering, connect, aggregate, and other operations to process target tables for new business needs. The common logic in SQL can be abstract components to enhance code reuse.
Task
A task performs various data operations . The following describes various task applications:
- A data synchronization node task is used to copy data from RDS to MaxCompute.
- A MaxCompute SQL node task is used to run MaxCompute SQL for data conversion.
- A flow task is used to perform a series of data conversions among several inner SQL nodes.
Each task uses zero or more data tables (data sets) as an input, and generates one or more data tables (data sets) as the output.
Tasks are divided into node tasks, flow tasks, and inner nodes. See the relationships between these tasks in the following figure:
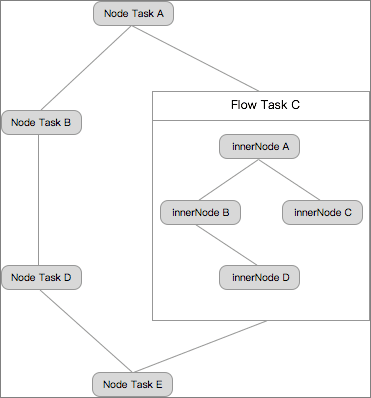
- A node task is a data operation. It can be configured to be dependent on other node tasks and flow tasks to form a Directed Acyclic Graph (DAG).
- A flow task is formed by a group of inner nodes that process a a work flow task. We recommend using less than 10 flow tasks. Inner nodes of a flow task cannot be dependencies of other flow or node tasks. A flow task can be configured to be a dependency of other flow and node tasks to form a DAG.
- An inner node is a node within a flow task. It basically has the same capabilities as a node task. Its scheduling cycle is inherited from the flow task scheduling frequency and cannot be configured independently. The dependency can only be dragged.
Data execution can be selected from an operation type, see Node type overview.
For details about task scheduling parameter configurations, see Scheduling configuration.
Instance
An instance is generated when a task is scheduled by the system or triggered manually. An instance is a snapshot that runs by a task at a certain time. The instance contains the task operating time, operating status, operating logs, and other information. For example:
Assume that Task 1 is configured to run at 02:00 each day. In this case, the scheduling system automatically generates a snapshot at the time predefined by the periodic node task at 23:30 each day. That is, the instance of Task 1 will run at 02:00 the next day. If the system detects the upstream task is complete, the system automatically runs the Task 1 instance at 02:00 the next day.
Submit
Script
A script is a code storage space for data analysis. The script code cannot be released to the scheduling system, and its scheduling parameters cannot be configured. It can only be used for data query and analysis.
Resources and functions
Resources and functions are both MaxCompute concepts. For details, see MaxCompute resources and MaxCompute functions.
In DataWorks, interfaces are used for resource and function management. Resources and functions managed through other MaxCompute methods cannot be queried in DataWorks.
Output name
The output name is the name of each task’s output point. If users set dependencies within a Alibaba Cloud account single tenant, a virtual entity that connects upstream and downstream tasks. .
If a task is set to form upstream and downstream dependencies with other tasks, the setting must be based on the output name. The task output name is also the input name for the downstream node.
DataWorks Scenarios:
Building a cloud platform for Internet big data application services
Features:
- Allows enterprises to focus on core businesses
The entire business infrastructure can be quickly migrated to Alibaba Cloud to optimize business productivity with available massive resources. Alibaba Cloud’s mature enterprise scaling solutions removes the need for enterprises to focus on scaling seamlessly and other related matters.
- Reduces investment and O&M costs
Greatly reduces material resources, labor, and R&D investment required for on-premises big data platforms.
- Security and stability
DataWorks comprehensive service capabilities foolproof data migration to the cloud and provides stable and assured performance.
Recommended combination:
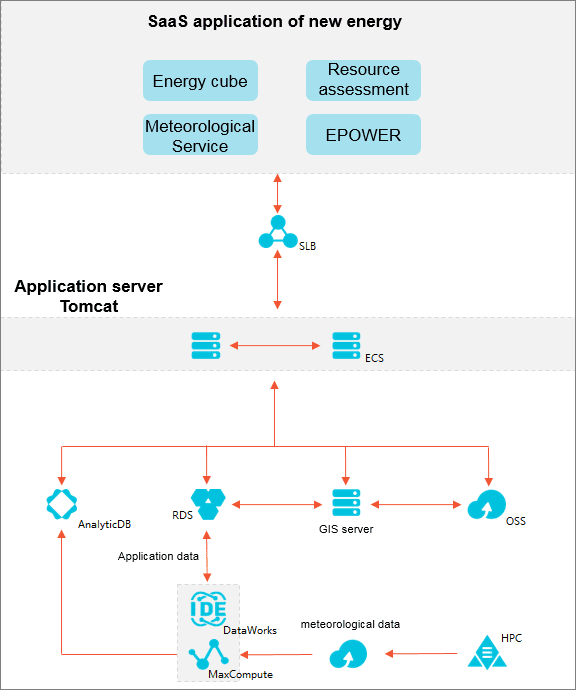
Weather queries and advertisement business log analysis
Features:
- Improves work efficiency
All log data is parsed through SQLs, increasing work efficiency more than five times.
- Improves storage utilization
DataWorks reduces overall storage and computing costs by 70%, and improves both performance and stability.
- Makes big data products easy to use
MaxCompute provides plugins for multiple open-source softwares, allowing you to easily migrate data to the cloud.
Recommended combination:
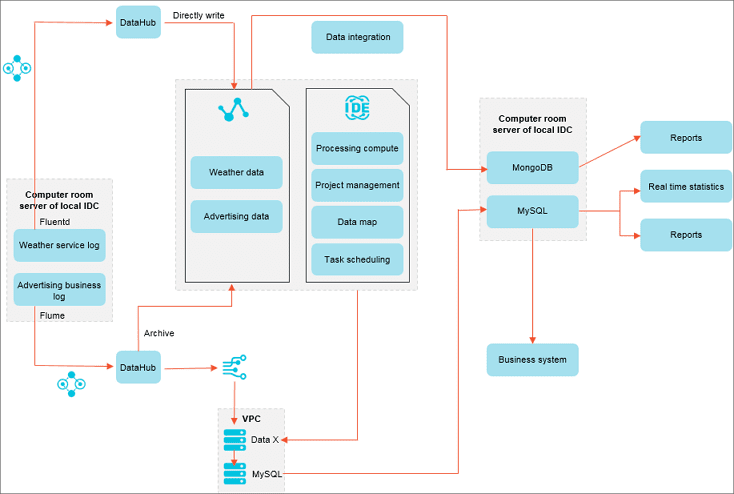
Delicacy management operations
- Improves business insights
MaxCompute’s computing capability can realize delicacy management operations for millions of users.
- Data-driven businesses
DataWorks empowers businesses by providing enhanced data analysis capabilities and effective monitoring functions.
- Quick response to business requirements
The DTplus ecosystem quickly responds to new business data analysis requirements.
Recommended combination:
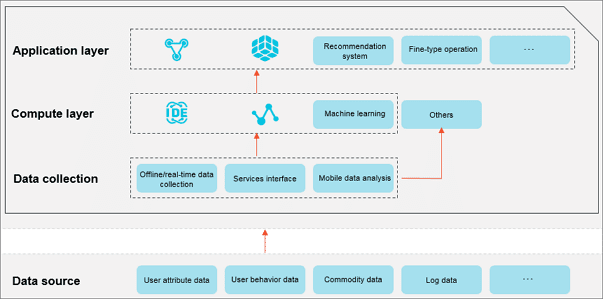
Data development process:
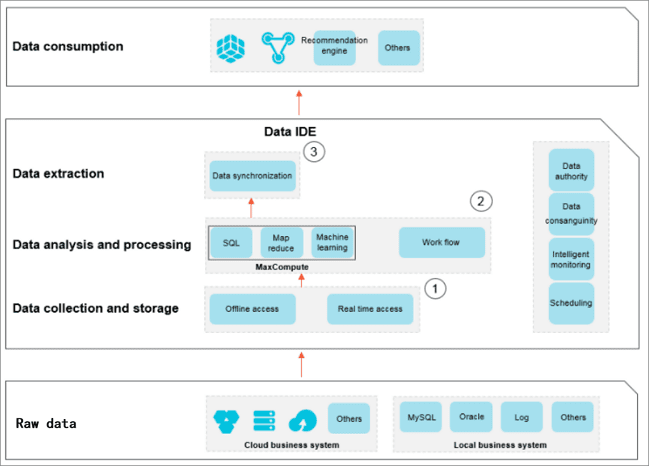
The data development process comprises data generation, data collection and storage, data analysis and processing, data extraction, and data presentation and sharing. See the following graphical process representation .
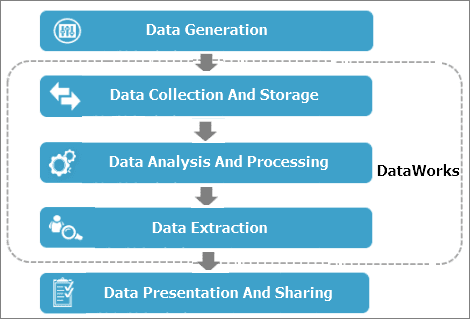
The data development process is as follows:
- Data generation
A business system generates a large amount of structured data every day. The data is stored in business system databases, such as MySQL, Oracle, and RDS.
- Data collection and storage
To use MaxCompute’s massive data storage and processing capabilities for data analysis, you must synchronize data from different business systems to MaxCompute.
DataWorks provides data integration services so you can synchronize various data types from business systems to MaxCompute according to predefined scheduling periods.
- Data analysis and processing
Next, you can process (MaxCompute_SQL and OPEN_MR), analyze, and mine (data analysis and data mining) the data on MaxCompute to find valuable information.
- Data extraction
The data after analysis and processing must be synchronized to your business system for further use.
- Data presentation and sharing
Finally, the results of big data analysis and processing are presented and shared as reports, geographical information systems, and in different accessible formats.
Simple mode and standard mode:
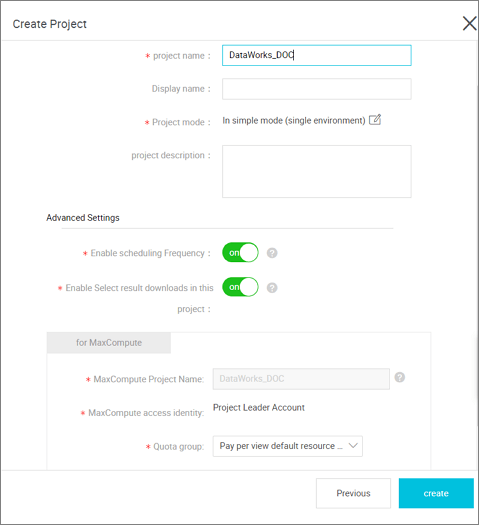
The new version of DataWorks introduces both simple and standard modes, this article introduces you to the differences between simple and standard modes.
Simple Mode
A simple mode refers to a DataWorks project that corresponds to a MaxCompute project and cannot set up a development and Production Environment, you can only do simple data development without strong control over the data development process and table permissions.
The advantage of the simple mode is that the iteration is fast, and the code is submitted without publishing, it will take effect.
The risk of a simple mode is that the development role is too privileged to delete the tables under this project, there is a risk of table permissions.
Standard Mode
Standard mode refers to a DataWorks project corresponding to two MaxCompute projects, which can be set up to develop and produce dual environments, improve code development specifications and be able to strictly control table permissions, the operation of tables in Production Environments is prohibited, and the data security of production tables is guaranteed.
- All Task edits can be performed only in the Development Environment, and the Production Environment Code cannot be directly modified, reduce the Production Environment code modification entry, as much as possible to ensure the Production Environment code stability.
- The Development Environment does not turn on task scheduling by default, avoid the development of environmental project cycle operation and production of environmental projects to seize resources, the stability of the operation of Production Environment tasks is better guaranteed.
- The Production Environment runs with a default production account, all the tables produced by the production account belong to the main account, you need to use production tables during the development process, all of which need to be applied separately, better control of table permissions.
Summary
In this blog, you’ve got to see a bit more about how to take advantage of all of the features included in DataWorks to help kickstart your data processing and analytics workflow. As you can see from the discussion above, Alibaba DataWorks works well in a variety of deployment scenarios. In fact, it has loads of features and works well with several data development strategies, allows for easy migration of workloads between various Data Sources and provides a means for easier Data Analysis, ML capabilities and security.