
Alibaba Cloud MaxCompute Resources
The big data computing service (MaxCompute, formerly called ODPS) is a fast and fully hosted GB/TB/PB level data warehouse solution.
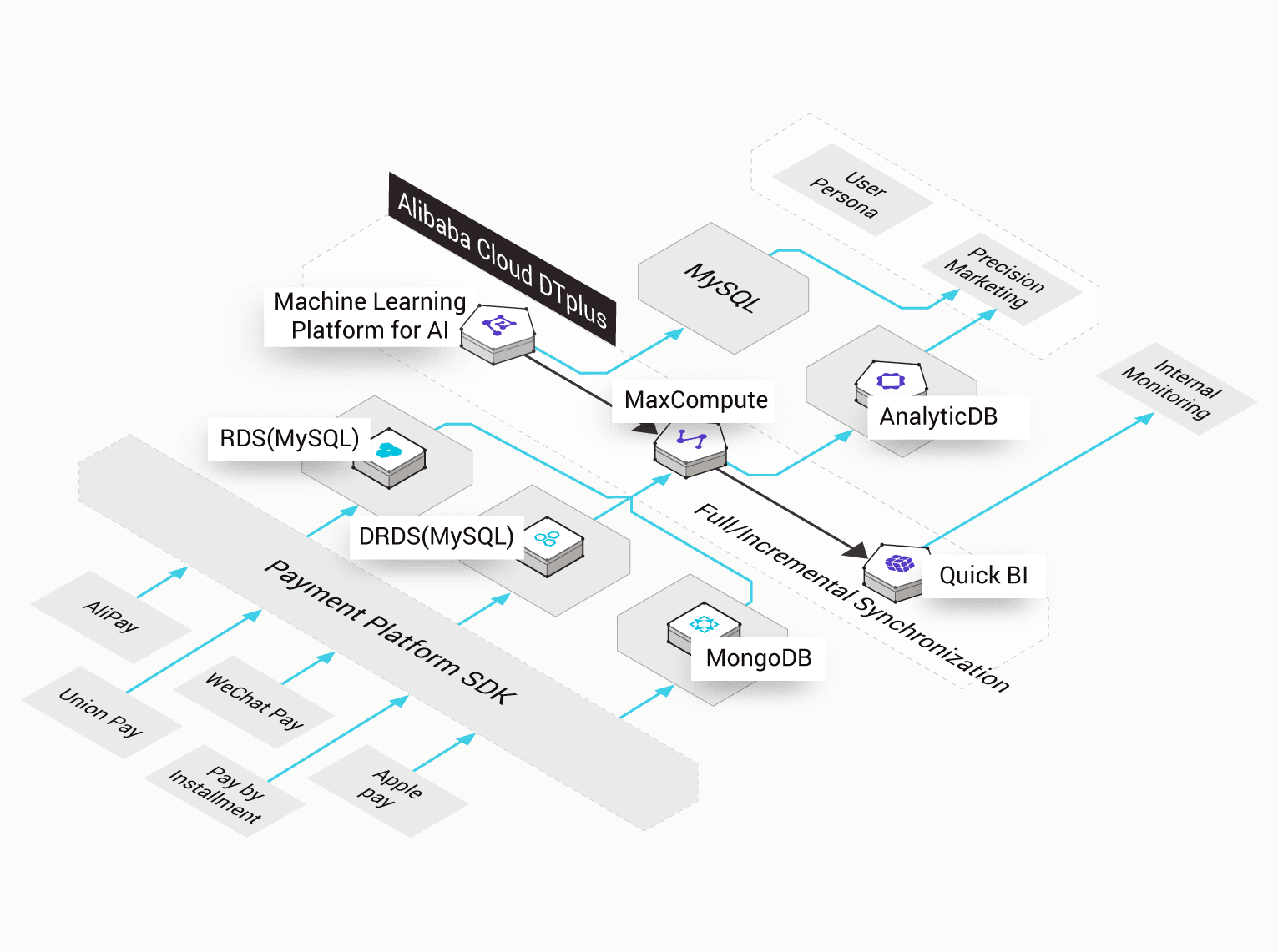
The big data computing service (MaxCompute, formerly called ODPS) is a fast and fully hosted GB/TB/PB level data warehouse solution. MaxCompute supports a variety of classic distributed computing models that enable you to solve massive data calculation problems while reducing business costs, and maintaining data security.
MaxCompute seamlessly integrates with DataWorks, which provides one-stop data synchronization, task development, data workflow development, data operation and maintenance, and data management for MaxCompute.
MaxCompute is mainly used to store and compute batches of structured data. It provides a massive range of data warehouse solutions as well as big data analysis and modeling services. As data collection techniques are becoming increasingly diverse and comprehensive,industries are amassing larger and larger volumes of data. The scale of data has increased to the level of massive data (100 GB, TB and even PB) that traditional software industry can not carry.
Product advantage
- Large-scale computing and storage
MaxCompute is suitable for the storage and processing of large volumes of data (up to PB-level).
- Multiple computational models
MaxCompute supports data processing methods based on SQL, MapReduce, Graph, MPI iteration algorithm, and other programming models.
- Strong data security
MaxCompute has stabilized all offline analysis for all Alibaba Group’s business for more than seven years, providing multilayer sandbox protection and monitoring.
- Cost-effective
MaxCompute can help reduce procurement costs by 20%-30% compared with on-premises private cloud models.
MaxCompute is a big data computing service that provides multiple built-in computing models to meet a wide range of data analysis requirements. This topic lists the enabling status of these computing models in different regions.
| Region | SQL | MapReduce | Spark |
| China (Beijing) | Enabled | Enabled | Enabled |
| China (Hangzhou) | Enabled | Enabled | Enabled |
| China (Shanghai) | Enabled | Enabled | Enabled |
| China (Shenzhen) | Enabled | Enabled | Enabled |
| China (Chengdu) | Enabled | Enabled | Enabled |
| China (Hong Kong) | Enabled | Enabled | Enabled |
| Singapore | Enabled | Enabled | Enabled |
| Malaysia (Kuala Lumpur) | Enabled | Enabled | Enabled |
| Indonesia (Jakarta) | Enabled | Enabled | Enabled |
| Australia (Sydney) | Enabled | Enabled | Enabled |
| Japan (Tokyo) | Enabled | Enabled | Enabled |
| US (Silicon Valley) | Enabled | Enabled | Enabled |
| US (Virginia) | Enabled | Enabled | Enabled |
| Germany (Frankfurt) | Enabled | Enabled | Enabled |
| India (Mumbai) | Enabled | Enabled | Enabled |
| UK (London) | Enabled | Enabled | Enabled |
The concept of resources
Resources is a concept that is unique to MaxCompute. To accomplish tasks using user-defined functions, or MapReduce, you must use resources.
- SQL UDF: After writing a UDF, you must compile it as a Jar package and upload the package to MaxCompute as a resource. Then, when you run this UDF, MaxCompute automatically downloads its corresponding JAR package to obtain the written code. The JAR package is one type of MaxCompute resource.
- MapReduce: After writing a MapReduce program, you must compile it as a Jar package and upload the package to MaxCompute as a resource. Then, when running a MapReduce job, the MapReduce framework automatically downloads the corresponding JAR package and obtain the written code. You can upload text files and MaxCompute tables to MaxCompute as different types of resources. Then, you can read or use these resources when running UDF or MapReduce.
Resource type
The max size that MaxCompute support for single resource is 500MB. Types of MaxCompute resources include:
- File
- Table: tables in MaxCompute
- Jar type, which is compiled Java JAR packages
- Archive type, which is the compression type, and is determined by the resource name suffix. Supported compression types include: .zip/.tgz/.tar.gz/.tar/jar
Add a resource
Command format:
add file <local_file> [as alias] [comment 'cmt'][-f];
add archive <local_file> [as alias] [comment 'cmt'][-f];
add table <table_name> [partition <(spec)>] [as alias] [comment 'cmt'][-f];
add jar <local_file.jar> [comment 'cmt'][-f];Parameters
- file/archive/table/jar: Indicates the resource type. For more information, see Resources.
- local_file: Indicates path of the local file, and uses this file name as the resource name. Resource name also acts as a unique identifier of a resource.
- table_name: Indicates table name in MaxCompute. Currently, external tables cannot be added into resource.
- [PARTITION (spec)]: When the resource to be added is a partition table, MaxCompute only supports taking a partition as a resource, not the entire partition table.
- alias: Specifies a resource name. If this parameter is not specified, the file name is used as a resource name by default. Jar and Python resources do not support this function.
- [comment ‘cmt’]: Adds a comment for the resource.
- [-f]: If a name is duplicated, this parameter can be added as a substitute to the original resource. If this parameter is not specified and the duplicate resource name exists, the operation fails.
Example
odps@ odps_public_dev>add table sale_detail partition (ds='20150602') as sale.res comment 'sale detail on 20150602' -f;
OK: Resource 'sale.res' have been updated.
---Add a resource named sale.res in MaxCompute.
Delete a resource
Command format:
DROP RESOURCE <resource_name>; --resource_name:a specified resource name.View the resource list
Command format:
LIST RESOURCES; Action:
View all resources in the current project.
Example:
odps@ $project_name>list resources;
Resource Name Comment Last Modified Time Type
1234.txt 2014-02-27 07:07:56 file
mapred.jar 2014-02-27 07:07:57 jarDownload resources
Use the following command format to download resources:
GET RESOURCE <resource_name> <path>;Action:
Download resources to your local device. The resource type must be file, jar, archive, or py.
Example:
odps@ $project_name>get resource odps-udf-examples.jar d:\;
OKSummary
In this blog, you’ve got to see a bit more about Alibaba Cloud MaxCompute Resources to take advantage of all of the features included in MaxCompute to help kickstart your data processing and analytics workflow.